Oracle數據庫架構導出及導入
♻從主庫導出資料庫架構至歷史庫
在該案例中我們將從CVCAA8REPORT主庫導出架構至新建的CVCAA8RPHIS歷史庫
因爲新建的庫中有系統用戶的存在, 所以首先我們需要排除掉他們知道我們需要導出哪些用戶
第一步先在新建的庫使用PL/SQL查詢存在的用戶SQL> Select * from dba_users;
執行完畢後我們可以在USERNAME欄位中看到當前新庫存在的系統用戶, 這些是我們需要從主庫導出前排除掉的用戶
接下來在主庫使用下面的語句查詢排除掉新庫已存在的系統用戶后需要導出的用戶列表
SQL> select * from dba_users where USERNAME not in ('user','user1','user2');
這裏的user,user1,user2就替換為上面在新庫查詢出來的系統用戶, 執行後輸出的用戶列表就是我們需要導出的用戶
使用exp導出
現在我們知道需要導出哪些用戶后, 可以開始準備導出了
下面是一個使用exp導出的模板, 使用紅色標注的地方需要根據實際狀況進行修改
⚠:exp導出在主庫OS中以oracle用戶執行
export ORACLE_SID=$SID
export NLS_LANG=$Character
exp $USER/$PASSWD file=/oradata/$SID_exp.dmp log=/oradata/$SID_exp.log owner=$user1,$user2,$user3,$user… statistics=none rows=n
⚠:$SID 為主庫的SID $Character 為數據庫的字符集, 兩個庫的字符集必須一致
$USER/$PASSWD 為用來導出的用戶名和密碼 file= 為導出文件的路徑位置 log= 為導出文件輸出的日志路徑
$user 為需要導出的用戶, 多個用戶間以逗號隔開 statistics=none 為不收集統計信息 rows=n 為不包含數據, 我們只需要導出架構
⚠:不要在PL/SQL裏面查詢字符集, 在OS裏使用SQLPLUS查詢SQL> select userenv('language') from dual;
例子:
export NLS_LANG=AMERICAN_AMERICA.AL32UTF8
export ORACLE_SID=aa8report
exp dbbackup/password file=/oradata/aa8report_exp.dmp log=/oradata/aa8report_exp.log owner=user,user1,user2 statistics=none rows=n
這裏我們使用dbbackup賬戶從aa8report將不包含數據的user,user1,user2三個用戶的架構導出到了/oradata目錄下名爲aa8report_exp.dmp同時輸出了一個名爲aa8report_exp.log的日志
路徑可以根據自己的實際情況進行修改, 這裏的owner=user就是我們上面從主庫篩選掉新庫最後得出的需要導出的目標用戶, 把他們帶到上面的exp導出的SQL語句裏, 用戶閒以逗號隔開
編寫完成後確認無誤在OS執行exp導出語句, 數據庫將導出至目標路徑上, 之後將導出的文件傳輸到新庫的伺服器上, 主庫架構導出這一步就算完成了
接下來我們就需要導入架構到新的數據庫了, 但我們現在還不能直接進行導入操作,
導入前需要確保新庫和主庫擁有相同的Profiles, Tablespace, Roles和Users
在這之前還需要先修改db files文件限制以免後續操作報錯
使用SSH工具登錄到新庫所在的Server
Command# su - oracle
首先確保在oracle賬戶下
Command# sqlplus / as sysdba
以sysdba用戶進入SQLPlus執行下面的操作
SQL> show parameter db_files;
查看DB Files的文件限制, 下圖是已經修改完成的, 默認的數值較小, 如不事先修改在創建Tablespace時會因爲限制報錯
![]()
SQL> alter system set db_files = 2500 scope = spfile;
將DB Files限制修改爲2500, 修改完成後重啓數據庫來生效
SQL> shutdown immediate;
關閉當前數據庫
SQL> startup
重新開啓當前數據庫
下面我們將使用Toad for Oracle®來從主庫導出Profiles, Tablespace, Roles和Users
打開Toad登錄主庫從頂部選擇Database > Export > Generate Database Script
首先我們導出Profiles配置文件
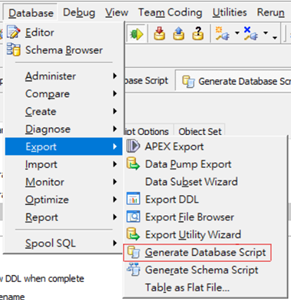
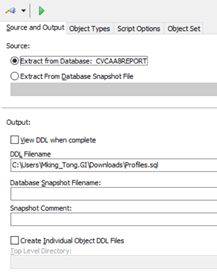
在Source and Output標籤頁Source:選擇第一項確認是你要導出的主庫
下面的DDL Filename選擇好目標路徑, 最後輸出的文件名為Profiles.sql
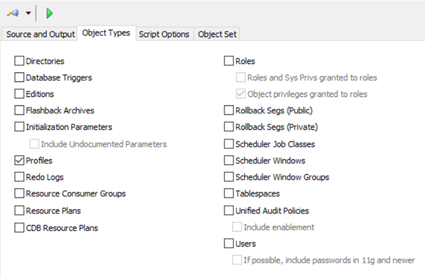
然後來到Object Types標籤頁, 勾選Profiles, 點擊頂部的![]() 來導出
來導出
導出完成後, 在下方會顯示 XX:XX:XX Info: DDL Extract Complete
重複上面的操作來導出Tablespace, Roles和Users
導出Tablespace表空間
在Source and Output標籤頁下的DDL Filename輸出的文件名為Tablespace.sql
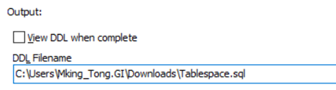
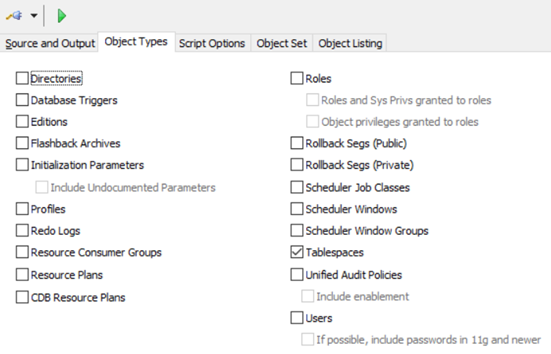
回到Object Types標籤頁, 勾選Tablespace,
點擊頂部的![]() 來導出
來導出
確認導出完成顯示 XX:XX:XX Info: DDL Extract Complete
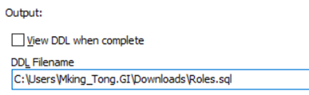
導出Roles角色
在Source and Output標籤頁下的DDL Filename輸出的文件名為Roles.sql
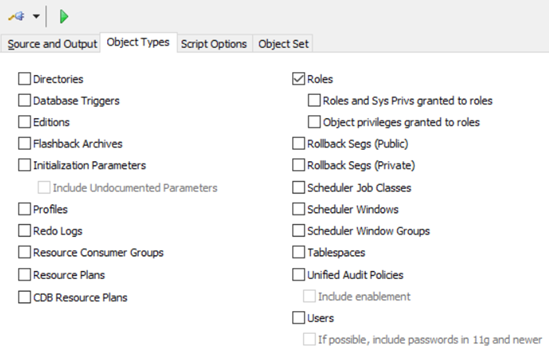
回到Object Types標籤頁, 只勾選Roles, 點擊頂部的![]() 來導出
來導出
確認導出完成顯示 00:00:00 Info: DDL Extract Complete
導出Users用戶
在Source and Output標籤頁下的DDL Filename輸出的文件名為Users.sql
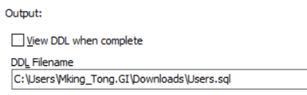
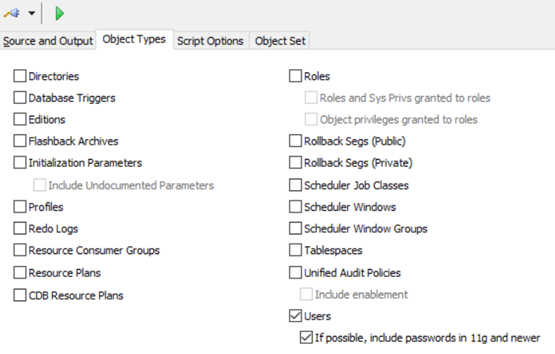
回到Object
Types標籤頁, 勾選Users和下面的選框, 點擊頂部的![]() 來導出
來導出
確認導出完成顯示 XX:XX:XX Info: DDL Extract Complete
現在我們已經得到了Profiles.sql , Tablespace.sql , Roles.sql, Users.sql 四個文件
首先我們先從Profiles.sql開始
在PL/SQL上左側的Objects面板我們可以看到主庫目前存在的Profiles如下圖
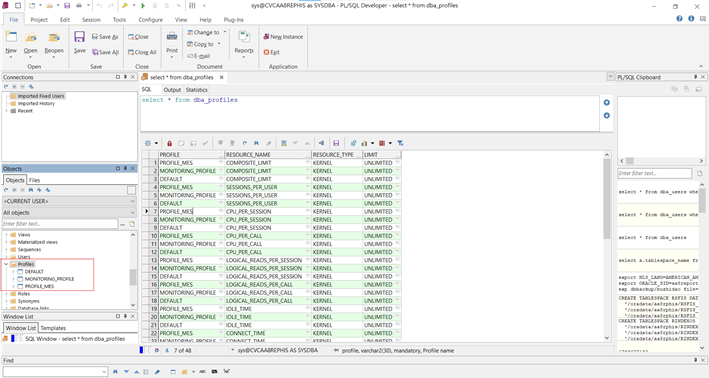
例如AA8REPORT上就有三個Profiles, 導出后的Profiles.sql就像下面這樣
 每一段就是一個Profiles, 可以通過第一行的名稱來辨識
每一段就是一個Profiles, 可以通過第一行的名稱來辨識
然後我們使用PL/SQL查看新庫的Objects面板, 和主庫的對比檢查重複的Profiles項目, 并在Profiles.sql中刪除重複的項目(確認段后刪除整段)
確認替換掉重複Profiles之後將Profiles.sql中剩下的語句在新庫的PL/SQL中執行, 執行完畢後新庫的Profiles即創建完畢與主庫一致
接下來我們需要用同樣的方法排除掉Tablespace.sql中的重複項目
在新庫的PL/SQL中執行以下命令來列出已存在的表空間
SQL> Select a.tablespace_name from dba_tablespaces a Order by a.tablespace_name;
我們要做的是將上面語句列出的表空間在從主庫導出的Tablespace.sql中刪除
打開Tablespace.sql, 它的格式差不多像這樣
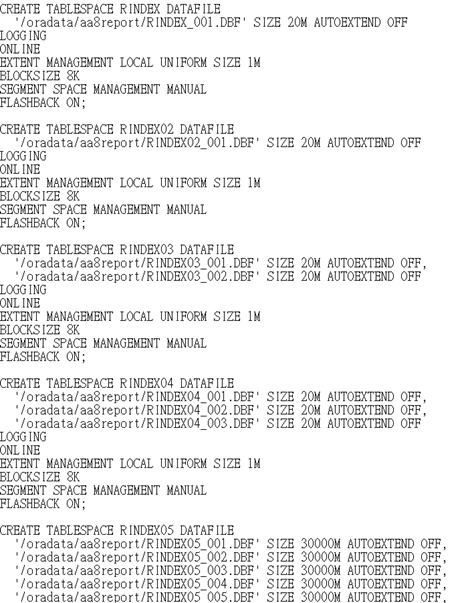
每一句創建表空間都以 CREATE TABLESPACE 開始並以分號結束, 每句以空行隔開, 第一行CREATE TABLESPACE後面是表空間的名字
將從新庫查詢到已存在的表空間名字與Tablespace.sql中的做對比, 并手動刪除存在的項目, 完成後全選複製粘貼到新庫的PLSQL中執行, 執行完畢後新庫的Tablespace即創建完畢與主庫一致
⚠:表空間TEMP為 CREATE TEMPORARY TABLESPACE TEMP TEMPFILE
⚠:如果目標庫SID和目錄路徑不一樣需要修改導出文件内的路徑
⚠:表空間創建時間可能會長達數分鐘至數小時, 期間不要斷開與數據庫的網路連綫
用同樣的方法排除掉Roles.sql中的重複項目
在新庫的PL/SQL中執行以下命令來列出已存在的Roles角色
SQL> Select * from dba_roles order by ROLE;
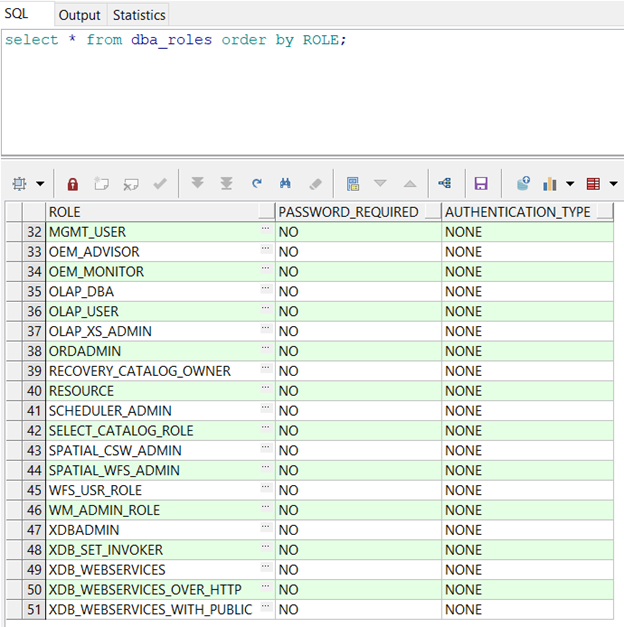
例如這裏新庫一共有51個已存在的Roles, 這些在主庫中導出的Roles中已存在, 所以在給新庫導入主庫的Roles時就需要刪掉這裏面列出的全部51個Roles角色, 他們是以A-Z字母排序
打開Roles.sql, 導出的格式大致如下
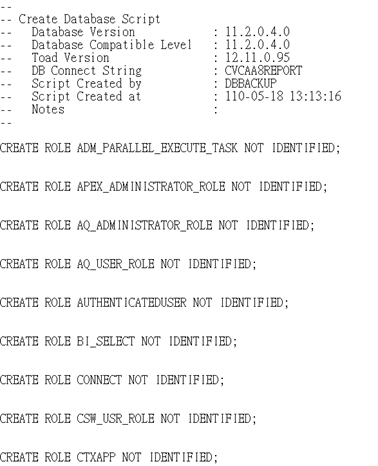
將上面新庫中查到的Roles從主庫導出的Roles.sql中刪除
再將篩選完的全選複製到新庫PL/SQL執行
執行完畢後新庫的Roles角色即創建完畢與主庫一致
用同樣的方法排除掉Users.sql中的重複項目
在新庫的PL/SQL中執行以下命令來列出已存在的Users角色
SQL> select USERNAME from dba_users order by USERNAME;
打開Users.sql, 導出的格式大致如下圖
有些User導出的語句會很長, 可以通過下一句 CREATE USER XXX 來判斷上一個User的語句結束
圖中例子中用紅綫區分了兩個用戶的創建語句
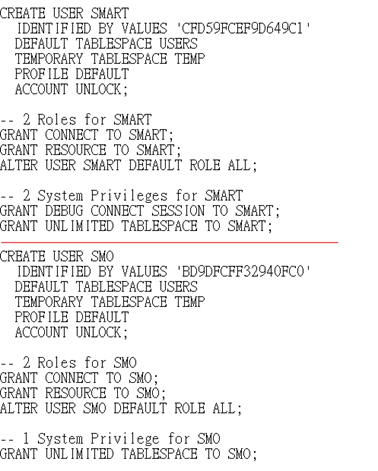
把從新庫查出來的重複用戶從裏面刪掉
再刪掉所有用戶的Object Privileges
即 -- XXX Object Privileges for XXX
完成後將編寫好的語句在新庫的PL/SQL執行
執行完畢後新庫的Users用戶即創建完畢與主庫一致
爲了防止主庫有DBLink的存在而新庫沒有所導致的大量報錯, 我們可以在導入之前就在新庫建立好和主庫一樣的DBLink
在主庫PL/SQL上左側的Objects面板我們可以看到目前存在的DBLink如下圖
⚠:如果這是在爲了建立測試庫來導入架構, 那麽此處建立DBLink應先跳過待後期開發人員有需求再建立
 例如主庫存在一個名爲AA8MES_LINK的Database_LINK
例如主庫存在一個名爲AA8MES_LINK的Database_LINK
在新庫PL/SQL上左側的Objects面板一樣找到Database links, 右鍵它點擊New...來新建一個DBLink
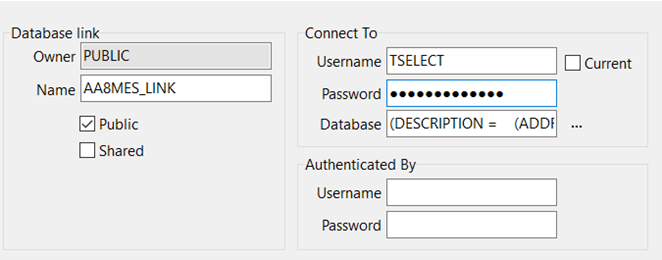
在Database link欄勾選下面的Public選框, Name和主庫DBLink中一致
Connect To欄的Username和主庫一致, 密碼主庫的欄位是不存在的, 這裏需要知道該賬號的密碼
Database欄直接寫入tns内容, 如果主庫直接是SID那麽説明主庫Server上已經有了寫好的tns文件, 這裏以後新建的庫都直接寫入tns内容, 點擊右邊的三個點
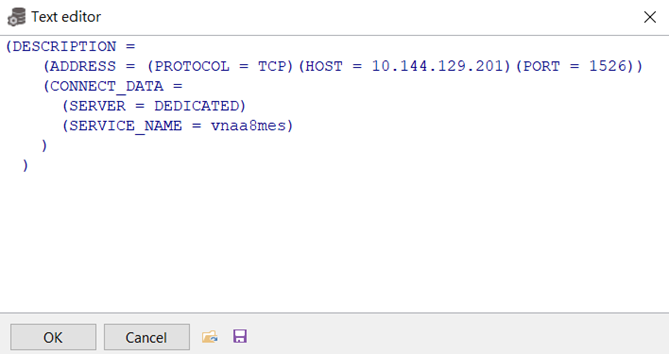
比如DBLink目標庫是CVCAA8MES那麽就將其TNS内容如上圖貼在框内, 完成後點OK
Authenticated By欄位不填留空, 點擊左下角的Apply按鈕應用建立DBLink
可以使用下面的語句來查詢DBLink的連接是否正常
SQL> select sysdate from dual@$DBLinkName;
$DBLinkName為你要查詢的DB_Link的名字, 當輸入@之後PLSQL會有提示框
這句話是用來查詢DBLink目標DB的系統時間, 如果查詢到沒有報錯且時間正確説明連接正常
導入前的步驟已經全部準備就緒, 接下來我們開始導入架構
⚠:導入架構前需要一個DBA權限的賬戶
開始imp導入
下面是一個使用imp導出的模板, 使用紅色標注的地方需要根據實際狀況進行修改
⚠:imp導入在主庫OS中以oracle用戶執行
export ORACLE_SID=$SID
export NLS_LANG=$character
imp $USER/$PASSWD file=/oradata/$SID_exp.dmp log= log=/oradata/$SID_imp.log full=y ignore=y
⚠:$SID 為被導入庫的SID $Character 為數據庫的字符集, 兩個庫的字符集必須一致
$USER/$PASSWD 為用來導入的用戶名和密碼 file= 用來導入的導出文件路徑位置
log= 為導入輸出的日志路徑 full=y 為導入全部數據 ignore=y 為忽略錯誤繼續執行
例子:
export ORACLE_SID=aa8rphis
export NLS_LANG=AMERICAN_AMERICA.AL32UTF8
imp dbbackup/password file=/oradata/aa8report_exp.dmp log=/oradata/aa8rphis_imp.log full=y ignore=y
這裏我們使用dbbackup賬戶將之前從AA8REPORT導出的架構數據導入到了AA8RPHIS新建的歷史庫中,
并在/oradata下輸出了一個名爲aa8rphis_imp.log的導入日志文件
⚠:完成後應檢查導入過程中出現的錯誤, 所有記錄都被輸出在log=/oradata/$SID_imp.log
在導入完成確認無誤之後, 我們將使用PL/SQL進行一次編譯
在PL/SQL中工具欄選擇Tools, 點擊Compile Invalid Objects 如下圖
再從底部的User選框中選擇<ALL USERS>來檢查錯誤
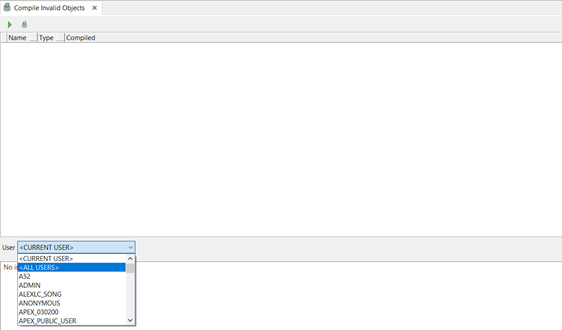
載入完成後你可以看到很多失效的項目, 點擊頂部的![]() 按鈕進行編譯
按鈕進行編譯
第一次編譯可能需要較長時間, 當編譯完成之後點擊![]() 按鈕來刷新列表檢查是否還有錯誤, 如果主庫本身不存在錯誤那麽現在新庫也不會產生錯誤, 如果錯誤產生説明你的架構導入遇到問題, 你需要根據錯誤來根據實際情況解決它 ; 如果主庫本身就存在錯誤那麽編譯完成後新庫應該和其保持一樣的錯誤來確保所有内容與主庫一致
按鈕來刷新列表檢查是否還有錯誤, 如果主庫本身不存在錯誤那麽現在新庫也不會產生錯誤, 如果錯誤產生説明你的架構導入遇到問題, 你需要根據錯誤來根據實際情況解決它 ; 如果主庫本身就存在錯誤那麽編譯完成後新庫應該和其保持一樣的錯誤來確保所有内容與主庫一致
至此, 你應已完成數據庫的架構導入
